The Co-Pilot That Refuses to Guess: Grounded RAG for PCBA Test Logs
A synthetic PCBA test-log pipeline, SPC that runs itself, and a citation-forced RAG co-pilot that refuses to answer when it isn't sure — built over eight weeks of evenings and weekends.
- Published
- July 3, 2026
- Author
- Hrushiekesh Kanjula Reddy
- Read time
- ~7 min
- Category
- engineering
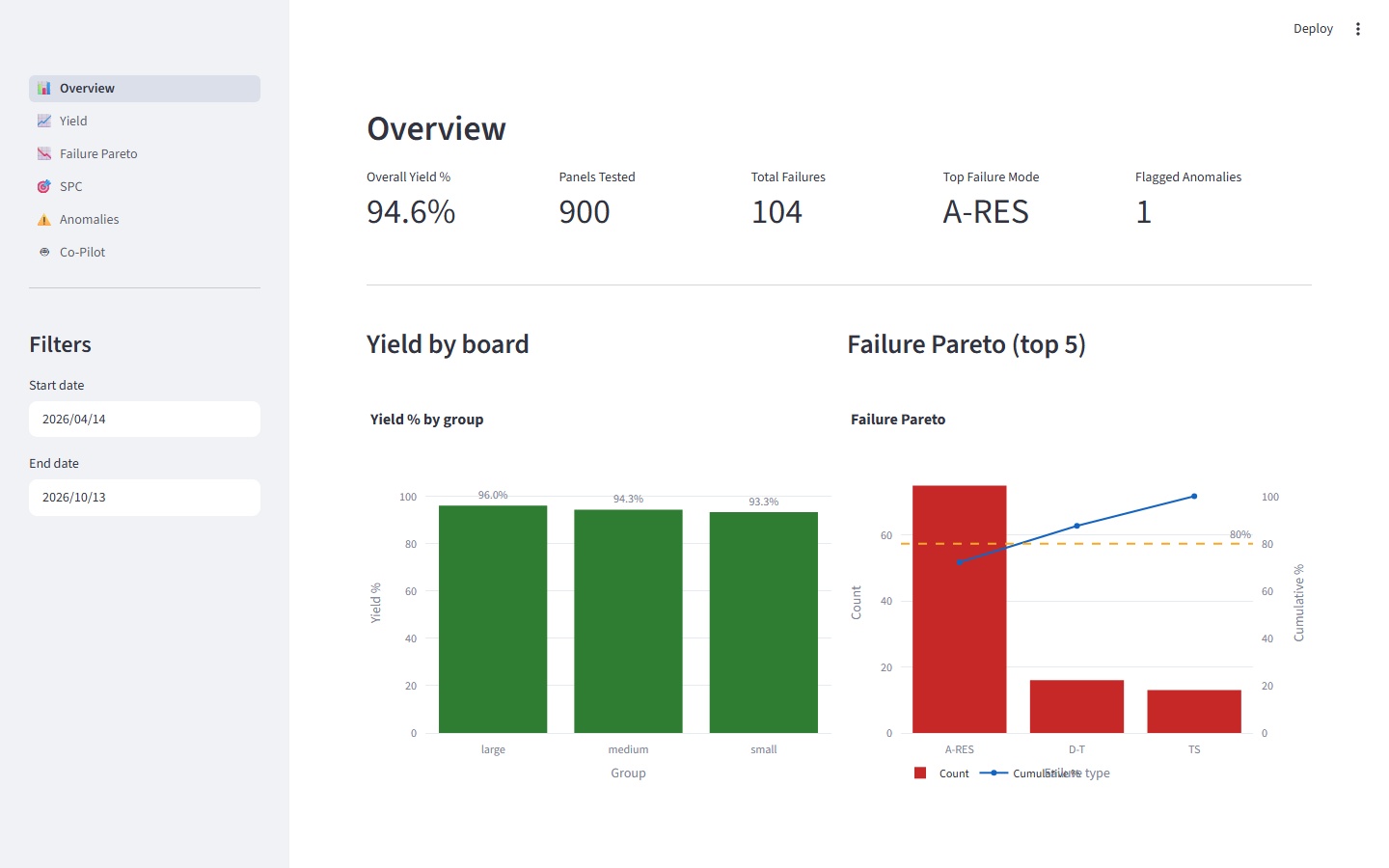
Every PCBA line that runs flying-probe or in-circuit testers emits structured logs — millions of measurement records per shift. The data is there. The analytics layer usually isn't. Factories either pay for a commercial suite or do it in Excel, and root-cause investigations still come down to "we saw something like this on lot 2024-W18, ask Kevin." That works fine until Kevin takes a week off.
Four gaps actually cost time on the floor. Logs sit in flat files, so correlating a shift's yield drop against a specific component family takes hours instead of minutes. SPC — Wheeler XmR charts, run-of-8, zone rules — is well understood on paper and almost never automated against real test data. Per-component failure-rate outliers, the kind where one part number is suddenly failing four times the line average, fall through because nobody's watching that specific slice. And root-cause questions like "why are these 0402s tombstoning?" end up as Slack messages to whoever remembers, instead of queries that return a cited answer in seconds.
I spent the last two months closing those four gaps for the open-source, local-first, single-engineer case — no cloud service, no vendor contract, one DuckDB file on a laptop. This is what shipped, and the three bugs that changed how I think about a whole class of problems.
What's actually running
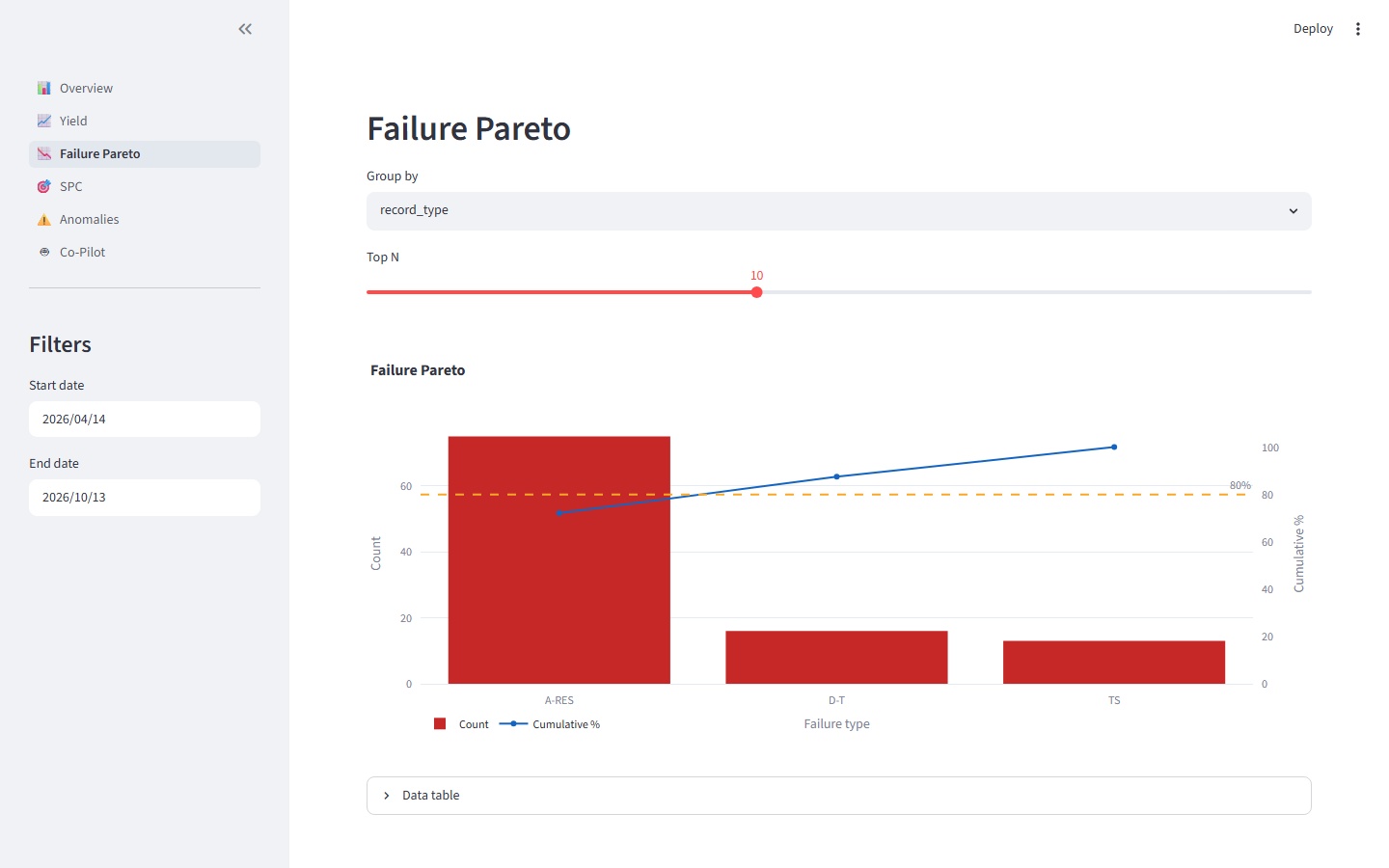
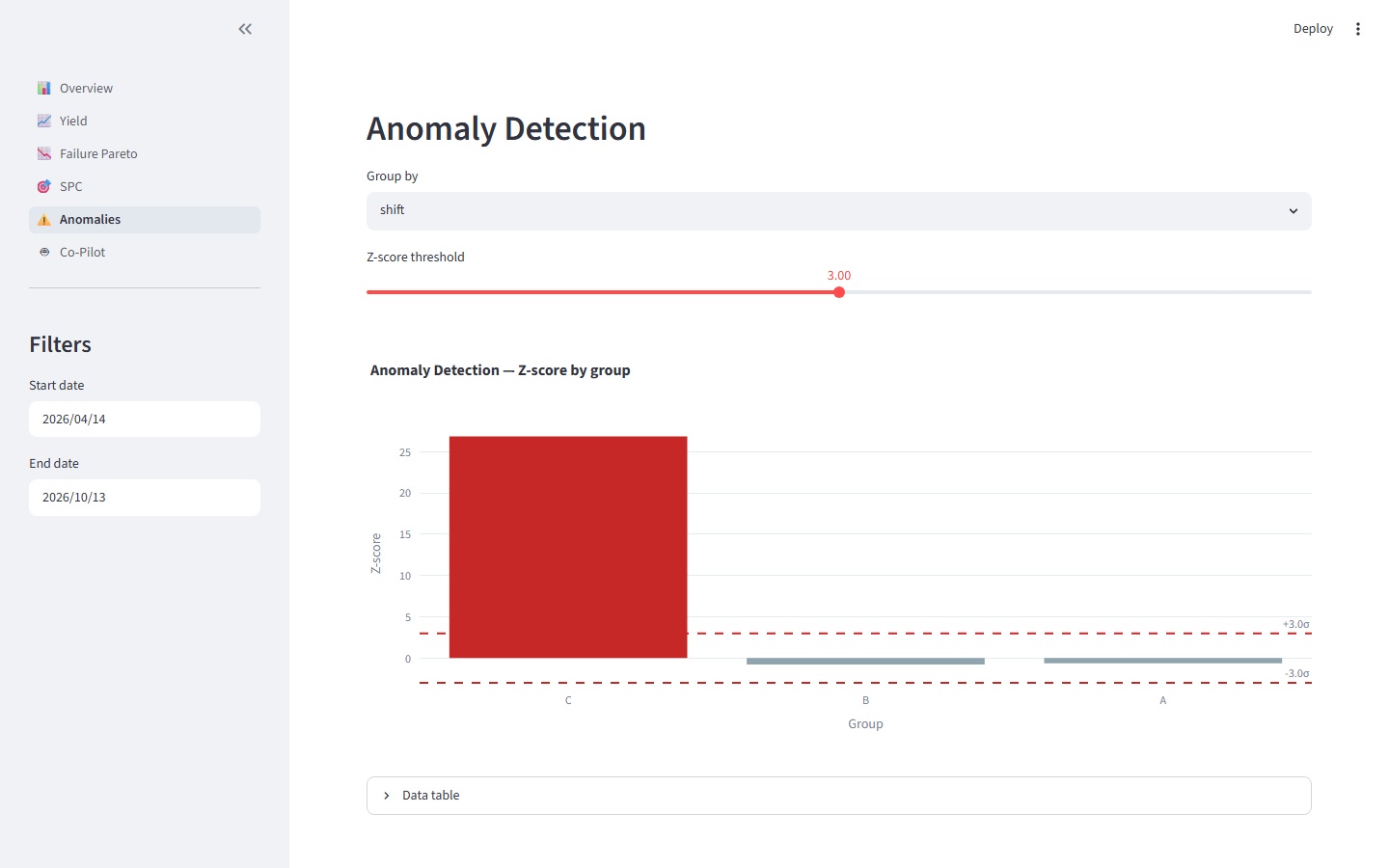
A synthetic HP3070/i3070 log generator produces Keysight Log Record Format output across three board profiles, with configurable fault correlation and shift-physics-aware timestamps — about a second per thousand panels. A parser turns that into a nine-table DuckDB schema: five dimension tables, one run table, three fact tables. On top of that sits an analytics library that's deliberately thin: four pure Python functions — yield_over_time, failure_pareto, individuals_chart for Wheeler XmR with run-of-8, and z_score_anomalies for leave-one-out, severity-first outlier detection. A six-page Streamlit dashboard renders all of it.
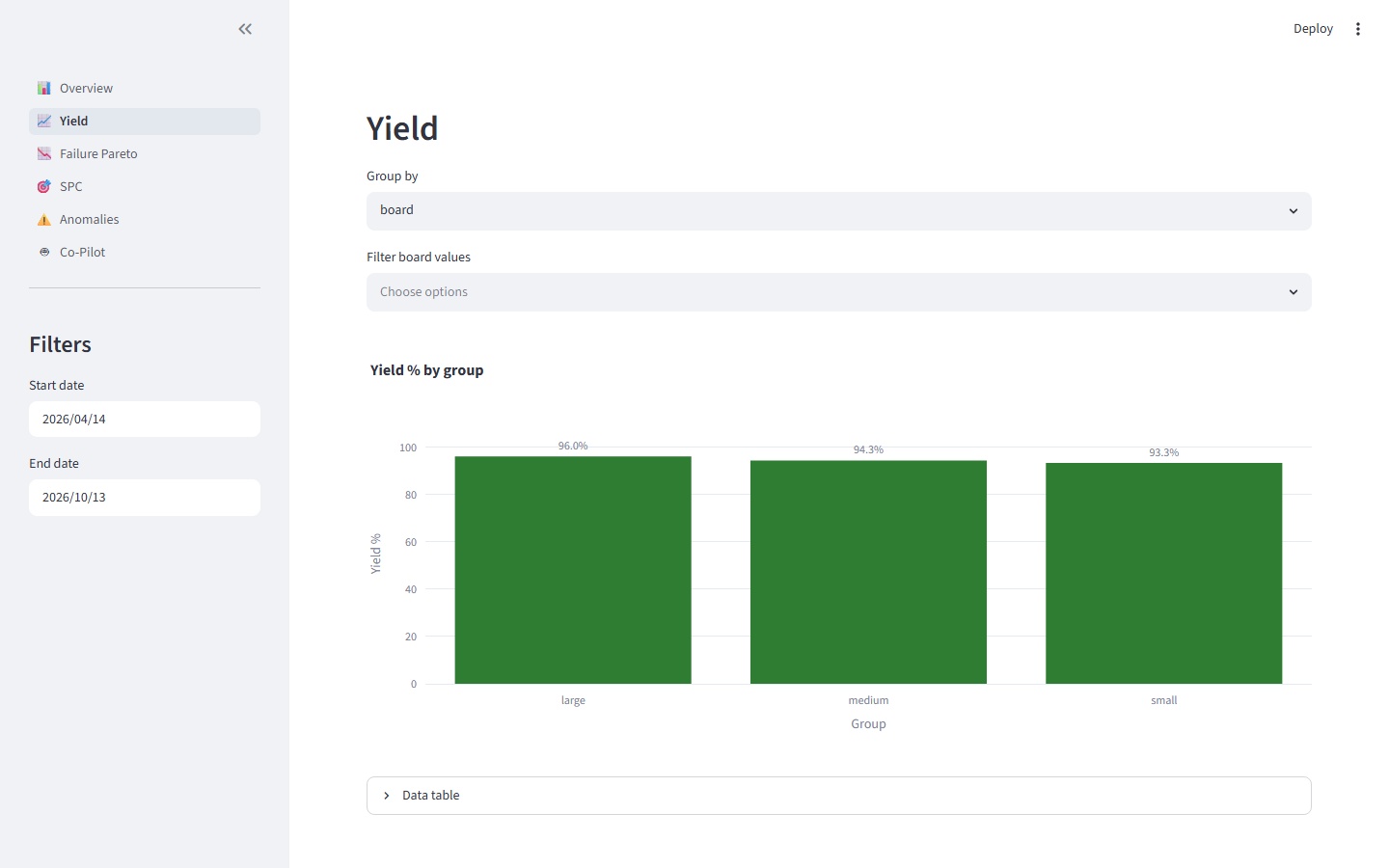
The Pareto and SPC pages are where the automation earns its keep. Failure-mode ranking that used to mean a pivot table now updates itself as new runs land; the individuals chart flags zone violations the moment a shift drifts, not two days later when someone finally opens Minitab.
The second half of the system is a hybrid RAG co-pilot grounded in an eight-document failure-mode knowledge base — opens, shorts, cold joints, missing components, misorientation, tombstoning, out-of-tolerance analog, insufficient solder — each citing the relevant IPC or J-STD section without quoting the copyrighted text itself.
Retrieval runs ChromaDB with cosine HNSW and rank-bm25 in parallel, fused with Reciprocal Rank Fusion at k=60. Vector search alone misses exact-match queries like "Q15" or "0402"; BM25 catches those. ChromaDB catches the semantic phrasing, like "lifted leads" matching "open joints." Fusing both beats tuning a weighted blend of either one alone.
Three bugs, three lessons
Every phase produced exactly one bug that changed how I think about a whole class of problem.
The shift-snap that lied about time. The synthetic generator schedules panels across three shifts. Shift C runs 22:00 to 05:59, so a raw timestamp of 02:00 belongs to the window that started the previous evening. My first cut drew a shift letter uniformly per panel, then tried to snap the timestamp into that shift's window — and the overnight wrap correction was a literal pass statement. A 02:00 draw randomly assigned to shift C would silently jump to 22:00 the same day. Run SPC trend analysis on that dataset and you'd get completely fictitious shift-to-shift yield deltas, confidently presented as fact.
The fix wasn't patching the wrap — it was deriving shift from time-of-day instead of drawing it independently and reconciling after the fact. _shift_for_hour(hour) returns the physically correct shift; _shift_window_start(ts, shift) snaps to the right window start. The broken pass became unreachable because the two values could no longer disagree. The lesson generalizes past this project: any time two correlated parameters are drawn independently and then "reconciled," the reconciliation step is where the bug lives. Derive one from the other and the whole class of error disappears.
The model that got retired mid-evaluation. The Phase 3 exit criterion was a live ≥8/10 evaluation against Gemini on a frozen ten-question dataset. First attempt ran two minutes thirty-one seconds and failed with a 404 — Google had retired gemini-2.0-flash out from under me. The entire wall-clock was gRPC's retry deadline timing out against a dead endpoint, not real API work. The fix was three lines: bump the model constant, update the test mirror, refresh the env example. The re-run passed 10/10 in 37 seconds, four times faster, entirely explained by not retrying something that no longer existed.
The lesson: a vendor model ID is versioned external state, not a constant in your codebase. DEFAULT_MODEL = "gemini-2.0-flash" reads like a config value; it's actually a contract with a remote API that can be revoked without notice. The follow-up — migrating off the already-deprecated google-generativeai SDK to its successor — landed the same day, and the live eval re-ran green without touching the model ID again.
The test that only broke under concurrency. A parser test passed every time in isolation and failed roughly 60% of the time inside the full suite — sometimes a partial-read assertion, sometimes a Windows file-lock error. The culprit was a test helper writing to a fixed path at the repo root. Run it alone and there's no contention. Run it inside the full suite and Windows file-watchers, antivirus, and parallel pytest workers all hit the same path mid-write. The fix was threading pytest's tmp_path fixture through every call so each test gets its own OS-temp file. A two-thread stress harness confirmed it: the shared-path version failed 484 times out of 800; the isolated version passed 800 out of 800.
Shared mutable state in tests is the same anti-pattern as shared mutable state in production — flakiness is just its most visible symptom. What made this one stick is that the test was genuinely correct in isolation. The bug only existed under concurrency, which is exactly the kind of failure that's easy to shrug off as "flaky" and re-run past. I now grep for repo-root file writes in every test-helper review.
The contract that kept the co-pilot honest
The answer() function refuses to respond unless four conditions all hold: retrieval returned at least one hit, the model emitted valid JSON, the response's sufficient field is true, and at least one cited chunk ID actually exists in the retrieved set. Hallucinated citations get dropped before they reach the user. The model never gets called on an empty retrieval — a failing lookup costs zero tokens. The refusal text itself is a fixed constant, not something the LLM generates, so there's no way for a "confident-sounding refusal" to sneak past the contract.
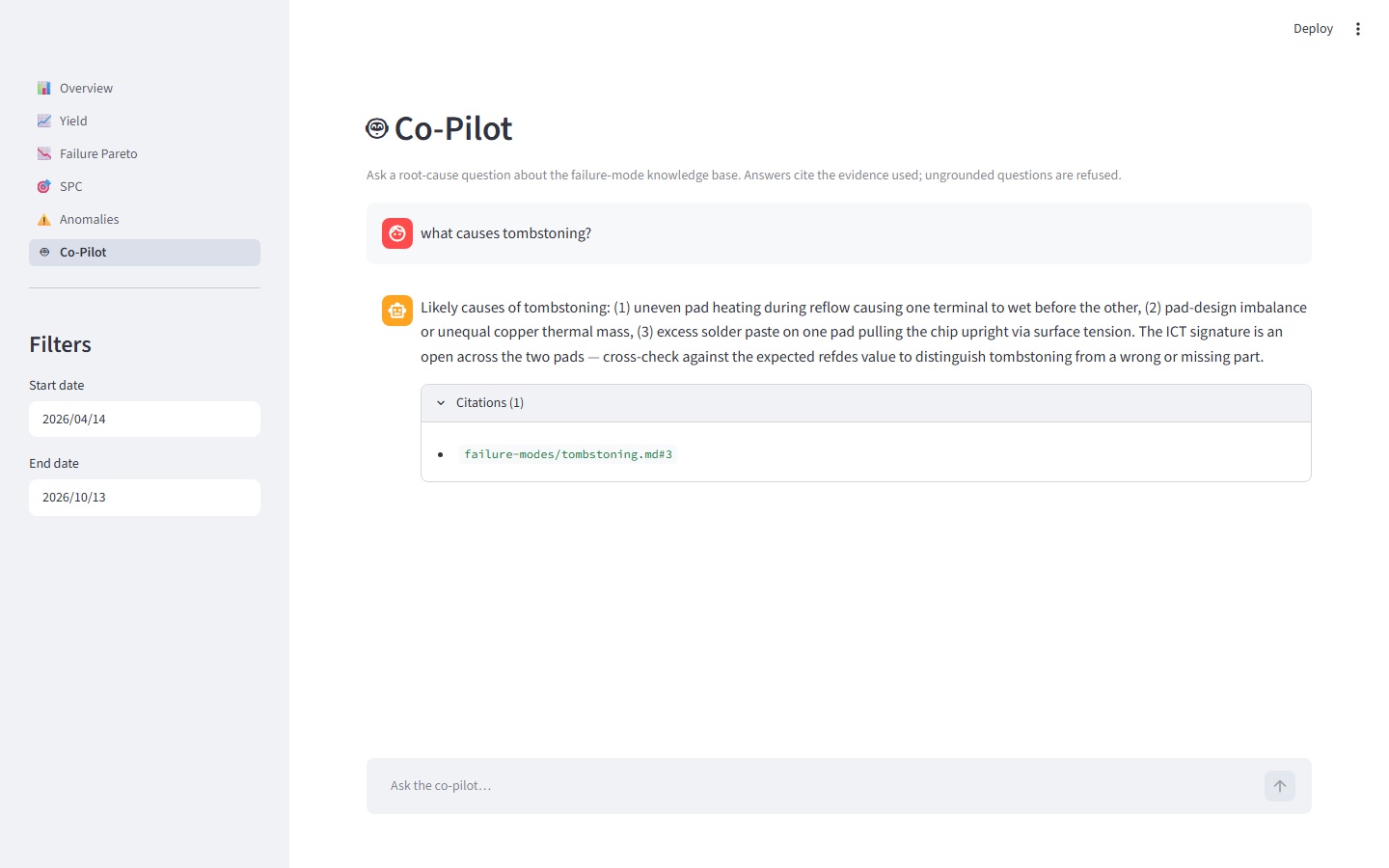
The eval discipline mattered as much as the retrieval architecture. Ten frozen questions, one per failure-mode document, checked two ways: an offline citation-pattern test with a stubbed retriever and stubbed LLM that runs in CI for free, and an env-gated live test that calls the real API and asserts at least 8 of 10 correct citations. That bar later tightened to 12 of 15 after a terse-query retrieval miss surfaced a real gap. Both bars are green as of the last run.
What I'd do differently
Migrate the vendor SDK the moment it's flagged as end-of-support, not when a 404 forces the issue. The cost of migrating later is rarely smaller than migrating now, especially on something your critical path depends on. Capture dashboard screenshots from CI instead of by hand — already fixed, with a headless Playwright pipeline that regenerates all six images and the demo gif from one command. And push real-data validation earlier in the schedule. The hard guardrail that real customer logs only touch the work network is correct, but it means realistic edge cases surface later than they should — a synthetic-but-realistic stress test would have caught a hardcoded shift="A" in the parser at the start of Phase 2 instead of midway through it.
Try it
The repo is public and MIT-licensed at flying-probe-copilot, with a scripted five-minute walkthrough in docs/DEMO.md and every plan, decision, and bug logged under docs/logs/. It's the sibling project to Assembly-Hub, where the same discipline — synthetic-first development, eval-as-code, guardrails logged before they're needed — runs against a live SMT line instead of a test-log spine.
I'm a Manufacturing/Process Engineer in the Dallas–Fort Worth area looking for a role that sits at the intersection of process engineering and AI. If your line is missing any of these four gaps, I'd like to talk.